
Wiki Guide: How to Extract Data from Wikipedia Using an API?
![Muninder Adavelli]()

Muninder Adavelli
Updated · Feb 11, 2024
Updated · Jan 02, 2024
Josh Wardini is our AI and automation guy. He started his internet journey in sales and marketing, u... | See full bio
If I was asked to describe myself using just a few words, I’d go with digital marketing expert, ex... | See full bio
This page may contain links to our partners’ products and services, which allows us to keep our website sustainable. Тechjury.net may receive a compensation when you sign up and / or purchase a product or a service using our links. As an Amazon Associate we earn commissions from qualified purchases. This comes at no extra cost to you. On the contrary, these partnerships often allow us to give you discounts and lower prices. However, all opinions expressed on our site are solely ours, and this content is in no way provided or influenced by any of our partners.
Machine learning algorithms find big data patterns and perform classification and prediction tasks based on the modeled training data. It has helped over 40% of companies increase productivity by automating simple tasks and creating predictions for business strategies.
Netflix's "Top Picks For You" section uses machine learning by looking at your history and finding similar content to watch.
To understand how algorithms find your next favorite movies and their impact on society, dive into the article below.
|
🔑 Key Takeaways
|
Machine learning (ML) algorithms use artificial intelligence (AI) to do the following:
Take Netflix, for example; there isn't a person manually checking your streaming history. Instead, it uses AI to find similarities and patterns from the shows you watch. Then, AI cross-references those patterns with Netflix's library to see if it has something similar or better to offer you.
The whole process is automated and works without extra supervision besides a model or training data.
Training data is a model of a successful prediction process. The machine inspects and training data models the behavior to determine an "appropriate prediction".
Some machine learning algorithms use training data, but others don't. Check out the short list of machine algorithm types below to learn how each deals with training data.
|
ML Algorithm Type |
Supervised |
Semi- Supervised |
Unsupervised |
Reinforcement |
|
|
Training Data Usage |
Full Training Data Usage |
Partial Training Data Usage |
No Usage of Training Data |
No Usage of Training Data |
|
|
Process |
Follows the training data to know how to make a prediction. |
Follows the partially trained data and explores excess data for patterns and model-building opportunities. |
Explores the untrained data for possible patterns and model-building opportunities. |
Generates data for later use by observing the machine’s interaction with the environment. |
|
|
Use Cases |
Data classification, Prediction |
Image classification |
Pattern Identification in Big Data |
Text Summarization, Dialogue Generation |
1. Supervised Machine Learning Algorithms
Here, the training data acts as a teacher or supervisor for the machine with fully labeled data. Any data fed into the machine is called variable X, while outcome data is called variable Y. After giving the machine the labeled data, it will map out an appropriate function based on what the training data dictates.
|
💡 Did you know? Supervised learning algorithms are the most commonly used algorithms. Businesses use it to assess risky investments, detect fraud, filter spam information and email, and classify images. |
2. Semi-Supervised Machine Learning Algorithms
Simply labeling data as variables X and Y can be pricey, so this algorithm uses partially labeled data instead. It follows the general process for using training data and explores unlabeled data for patterns and possible connections. Exploring unlabeled data is considered model-building.
|
🎉 Fun Fact: Model-building helps data analysts extract patterns, information, and insight from unlabeled big data. Human processing of big data can take time, but semi-supervised learning algorithms can do it faster. This learning algorithm is famously used in image classification, as well. |
3. Unsupervised Machine Learning Algorithms
Unsupervised learning algorithms use purely unlabeled data. The machine extracts patterns, trends, and useful information from given data sets.
These algorithms find undetected, unexpected patterns that help draw meaningful insights for the person using the machine.
|
✅ Pro Tip: Unsupervised learning algorithms are best used for pattern detection and descriptive modeling. |
4. Reinforcement Machine Learning Algorithms
Machines using this algorithm observe their own interaction with the environment and keep the data for later interpretation.
Fields using ML algorithms often utilize it to maximize rewards and minimize risks.
|
🎉 Fun Fact: Reinforcement learning algorithms are used in language and image processing, recommendation systems, and gaming. |
Learning algorithms vary in process and data consumption, but they all have real-life functions. Learn more about the functions and applications of algorithms in the next section.

Many people still doubt AI’s usefulness and safety, especially in fields involving human care and interaction. However, despite this hesitancy, the fact remains that AI can increase productivity by up to 40%. Its impact is undeniable.
Over time, technology has been able to fulfill more community needs. AI and machine learning have proven their worth through countless real-life applications.
Here’s a closer look at how machine learning algorithms are utilized daily.
Artificial intelligence transformed the process of learning. It can simulate and respond to real-life conversations, which is perfect for language practice.
AI-powered voice-recognizing tools can also help develop language-speaking skills and build confidence and fluency among learners. This technology accurately reflects the user's intonation, pronunciation, stress, and rhythm.

AI's ability to recognize patterns and trends helps personalize and elevate the language learning experience. Some ways to do this are through:
|
🎉 Fun Fact: Machine-generated data accounts for 40% of the Internet's data. Using machine learning algorithms has become so common that it's now a major contributor to the world's digital data. |
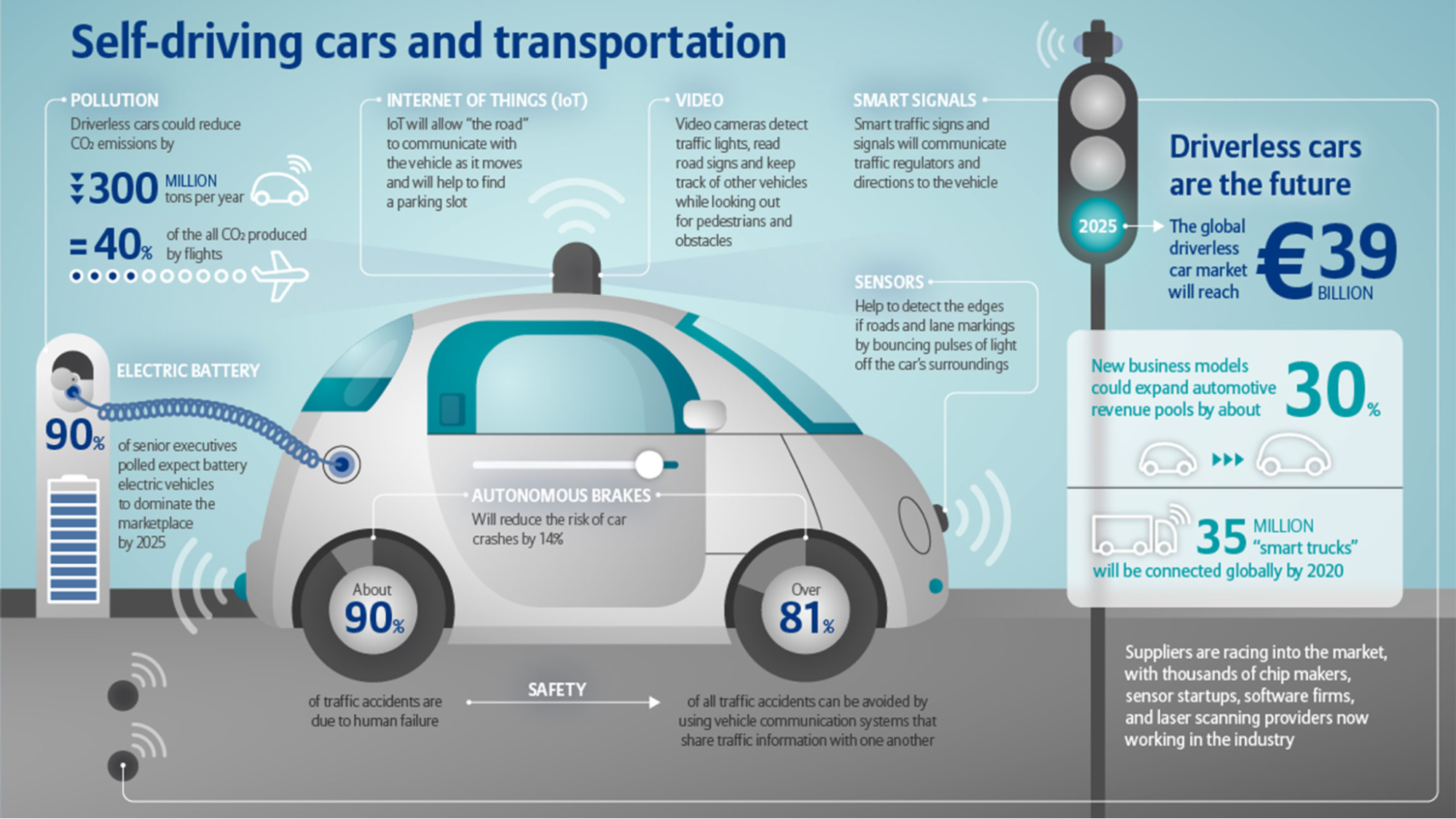
Automobile companies first used AI for object-detecting sensors, parking aids, and avoiding accidents. Toyota, Audi, Volvo, and Tesla are among the first companies to do this.
AI integration soon followed on the automobile parts below:
Later on, emergency features like brakes, blind-spot monitoring, assisted steering, and driver behavior readers transformed the automobile industry. These capabilities gave rise to self-driving cars, one of AI’s most promising endeavors.

The healthcare industry integrated AI into medical treatments, drug discovery, and industry development. Machines help detect illnesses and identify cancer cells. Many healthcare facilities also use AI-powered software and tools to review patient data and records for an earlier diagnosis.
AI and machine learning recently entered the drug recovery and intervention industry. AI helps build computer-recommended support groups and communities for individuals going through drug recovery. Other uses of AI within the community include:

AI predicts risks, side effects, and drug intolerance. It also helps find new drug combinations for patients with multiple medical conditions and track symptoms through wearable devices.
Additionally, algorithm-powered bots serve as 24/7 chatbots when human chat support isn't available.
The field of agriculture uses AI to face the following uncontrollable factors:
AI integration reduces manpower needs while increasing productivity. AI-powered drones help tend fields, and algorithms build crop yield strategies. Drones and robots identify plants’ weeding, irrigation, and spraying needs using sensors to operate on their own.

Machine learning algorithms also help with price forecasts, agricultural market predictions and insights, and crop and insect disease diagnoses.
|
💡 Did You Know? AI is one of the most promising technology fields in 2023. Industries like healthcare, transportation, and logistics focus on incorporating AI into their products and systems. |
Machine learning algorithms of all kinds make it possible for technology to function independently. The following are the most common algorithm types in the industry and their use cases.
Linear Regression is a supervised learning algorithm. It produces continuous predictions based on the data given.
If you're selling a house, the price itself is considered the output variable. Your selling price depends on input variables like the house's age, location, area size, material foundation, etc. The better the input variables are, the higher the selling price will be. 
Computations like in real estate pricing can be done manually. However, linear regression algorithms help avoid human error and achieve more accurate predictions.
Linear Regression algorithms are perfect for economics, market and financial analysis, and environmental health prediction.
Logistical Regression is a supervised algorithm that only produces two outcomes, or as the industry calls it, binary values.

If you used Linear Regression to find the price of the house you're selling, the question turns to "Will the house sell or not?" in Logistical Regression.
It still considers other variables like the house's age, location, area size, and material foundation. However, its ultimate prediction is limited to Yes or No.
Logistic Regression’s ability is applicable to fraud transactions, or positive and negative audience responses in campaigns.
Linear Discriminant Analysis is a supervised classification algorithm used in pattern classification. It inspects the distance between items in the data and identifies similarities to establish two categories.

This algorithm works well with multidimensional items like 3D figures, images, and complex datasets. It helps with facial recognition, pattern recognition, decision-making, and data visualization.
The K-Nearest Neighbors is a supervised classification algorithm that categorizes items based on proximity. KNN stores labeled data and awaits classification requests for execution—which earned it the title of a "lazy learning" model.

The example above introduces a dataset into the existing positive and negative review data system with a KNN algorithm. The algorithm will inspect your new item's similarities and distance between the two categories to find which fits best.
KNN's ability to identify observational differences and distance makes it perfect for image classification, computer vision, and content recommendation.
Decision trees got its name from its tree-like structure. It's a supervised algorithm that predicts outcomes and classification.
New items are called the root node, which are similar to training data. After evaluation, the node branches out towards new predictions and outcomes called leaf nodes. The process continues until it reaches an overall decision. 
Anyone can use decision trees for anything. For example, the decision tree below helps you decide whether or not to accept a job offer. It compares attributes like location and transportation support to see if the job meets the worker's conditions.

Practical usage for decision trees involves visitor churning in websites, forecasting market growth, and identifying disease probability among patients.
The Random Forest algorithm is made up of multiple decision trees. The more decision trees are available, the stronger their decision or prediction will be.
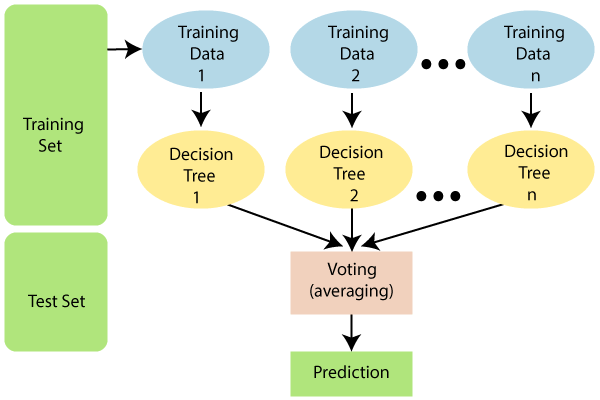
Random Forest averages the outcome from multiple decision trees for a stronger prediction—perfect for high-speed and accurate predictions.
As for real-world applications, this algorithm is useful in finance, healthcare, and e-commerce. It evaluates loan eligibility, credit card protection, disease prediction, and product recommendations.
Adaptive Boosting, or AdaBoost, is a supervised learning algorithm that uses decision stumps to build strong models. Decision stumps are decision trees that didn't go past one level of the leaf node, often labeled as weak classifiers.

AdaBoost takes weak classifiers and uses training data to improve them. Once the weak classifiers improve and earn a higher score, the improved classifier trains other weak classifiers again. A sequence occurs until the overall error rate decreases.
This algorithm works with high-level regression prediction, classification, and outliers. It predicts customer churn rates, topics of interest among customers, and medical diagnoses.
Naïve Bayes is one of the industry's most accurate, fastest, and most reliable text classification supervised learning algorithms.
The algorithm converts new data into a frequency and likelihood table and calculates probability using the Bayes theorem.

The illustration uses the Naïve Bayes algorithm to find the probability of getting a certain shape. If you're looking for a circle, you'll find that you have an equal probability of getting triangles and diamonds. Larger datasets with more diverse items can yield different results.
Naïve Bayes is used to classify text-based items like spam email, article categorization, and sentiment analysis.
Learning Vector Quantization
This supervised algorithm lets you build your own dataset by selecting what to keep and let go. Once you make a request, LVQ compares it with your dataset to find the right category.

Similar items clustered together are categorized—each composed of countless neurons.
Learning Vector Quantization best works with pattern recognition, data mapping, and image-based data classification.
A Support Vector Machine is a supervised algorithm establishing a decision boundary between two datasets, also known as a hyperplane.
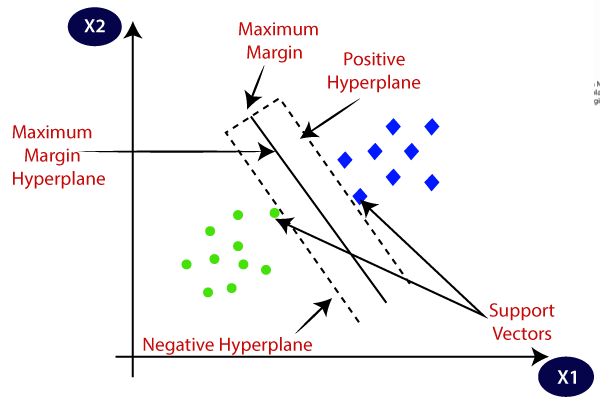
Once it establishes a hyperplane, the machine notes the attributes of the two categories. Incoming data will undergo comparison to the attributes and categorization upon entry.
Although the algorithm applies to regression and classification tasks, it's ideal for classifying new data.
Support vector machine is ideal for complex datasets that need quick and efficient categorization. Some examples are handwriting recognition, email classification, and face detection.
Machine learning is now intertwined with daily life, and it's not going anywhere.
Supervised machine learning algorithms are changing forecasting, prediction, and classification standards. Industries like agriculture, finance, education, healthcare, and transportation use more of it to improve their products and services.
The rise of AI-powered devices and machine learning integration in the most common technology brightens the future.
Machine learning is a subtopic of AI. It allows systems and applications to read data, identify patterns, and perform tasks without being programmed or manually handled.
Machine learning yields improved accuracy, faster decision-making process, and work efficiency.
Data cleaning is the most important part of machine learning because it depends on datasets to train and function. With properly trimmed, organized, and labeled data, machine learning can do its part.
SHARE:
Your email address will not be published.
Updated · Feb 11, 2024
Updated · Feb 11, 2024
Updated · Feb 08, 2024
Updated · Feb 05, 2024



