
Wiki Guide: How to Extract Data from Wikipedia Using an API?
![Muninder Adavelli]()

Muninder Adavelli
Updated · Feb 11, 2024
Updated · Oct 25, 2023
Harsha Kiran is the founder and innovator of Techjury.net. He started it as a personal passion proje... | See full bio
Girlie is an accomplished writer with an interest in technology and literature. With years of experi... | See full bio
This page may contain links to our partners’ products and services, which allows us to keep our website sustainable. Тechjury.net may receive a compensation when you sign up and / or purchase a product or a service using our links. As an Amazon Associate we earn commissions from qualified purchases. This comes at no extra cost to you. On the contrary, these partnerships often allow us to give you discounts and lower prices. However, all opinions expressed on our site are solely ours, and this content is in no way provided or influenced by any of our partners.
With the world generating 1.145 trillion MB of data daily, humans can't analyze and structure it alone. This is where data processes help.
Web scraping and web crawling are methods of gathering data over the Internet. While both terms are used interchangeably, these two approaches are very different.
Continue reading to discover the difference between web scraping and web crawling and which method suits your data-gathering projects.
|
🔑 Key Takeaways
|
Web scraping and web crawling are two different data extraction activities. However, they usually overlap—so it's easy to interchange these terms.
Website crawling involves gathering URLs from web pages for indexing and archiving. This process is usually automated using web crawler agents or “spiders.”
Meanwhile, web scraping involves collecting specific data sets from web pages. It's not limited to URLs.
Take a look at each method to see the distinction between the two processes:

To gain a better understanding of their differences, you must grasp what each process means and how they work. Read on.
To crawl the Internet means visiting URLs through hyperlinks. It also means reading the web pages’ meta tags or content for proper indexing.
The best web crawlers worldwide are popular search engines like Google and Bing. They also have the best web crawling architecture.
You can summarize the web or data crawling process in these four steps:
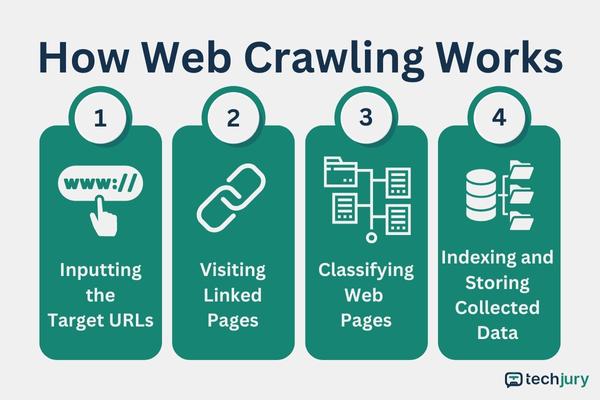
Step 1: Inputting URLs - The web crawler API requires URLs to crawl the web.
Step 2: Visiting All Linked Web Pages - The web crawler API or software visits all pages linked to the starting URLs.
Step 3: Classifying the Web Pages - The web crawler categorizes the web pages according to their meta tags and content.
Step 4: Indexing and Storing the Collected Data - Upon getting the needed data, the tool will index and store it.
|
📝 Note The gathered data from web crawling are only URLs and meta information. If a crawler collects other data sets, the process will become web scraping. |
Web scraping is the process of extracting various data sets from websites. It can be small or large scale, depending on the goals of a scraping project.
Automatic web scraping is more common today than manual "copy/paste." However, manually collecting data from web pages can still work for smaller projects.
Here is a summary of how the web scraping process works:

Step 1: Sending the Request - The web scraper sends a request to the target site.
Step 2: Receiving the Requested Data - The web scraper receives the requested site in HTML.
Step 3: Parsing the Data - The web scraper parses the HTML content to extract a specific data set.
Step 4: Storing the Data - The web scraper stores the data in a readable format for further analysis. Some of these formats are JSON, XML, and spreadsheets.
|
📝 Note The collected data may include but is not limited to URLs. A web scraper only goes as far as collecting its target data. |
Screen scraping is a form of web scraping. It gathers data by capturing the user’s screen—typically with the user’s consent.
Financial services usually use this to collect and assess user data. It's also ideal for managing customer bank accounts.
APIs gradually replaced screen scraping due to privacy and security concerns. Another reason was screen scraping takes more work to maintain.
Banking institutions now provide APIs for transferring data without accessing customer accounts.
|
👍 Helpful Article Web scraping and API are two standard methods used to extract data. While both make the extraction process easier and automated, each method works differently. Discover the distinctions between web scraping and API to determine which method is the best for data extraction. |
The distinctions between web crawling and web scraping lie in their scope, components, goals, and legal concerns. Here is an overview of the key differences between the two:
|
Key Aspects |
Web Crawling |
Web Scraping |
|
Scope |
Visits and collects URLs for indexing |
Extracts specific data sets from web pages not limited to URLs |
|
Goals |
Commonly large scale |
It can be small or large-scale |
|
Components |
Uses web crawler agents or spiders |
Uses web scraper APIs with parsers, screen scrapers, or manual copying/pasting |
|
Legality |
Needs to visit every page within a website through hyperlinks |
Targets specific web pages for the desired data set |
Take a look at how the two processes differ in particular aspects to gain more insight.
Web crawling projects are usually large-scale, as seen in search engines. However, it can also be smaller if the project integrates it into a web scraping project.
Meanwhile, web scraping can be small-scale or large-scale, depending on the target data set. Manual data collection from a few web pages can even be web scraping if it can extract the target data.
Web crawling indexes web pages by following and collecting URLs from hyperlinks. This data may also include metadata for classification purposes.
Web scrapers extract specific data sets and can be “anything.” It is also unnecessary for a web scraper to follow all the links related to a website.
|
📝 Note Unlike web crawlers, web scrapers are usually limited to URLs containing the target data. It is only possible to visit web pages with the needed data set. |
Web crawlers perform their tasks by sending requests to their target URLs. Some web crawlers do it by emulating a regular browser. Otherwise, servers can block them due to bot-like behaviors.
Crawlers also use a link extractor and hypertext analyzer to collect the URLs and analyze meta information.
Most web scrapers also have “web crawlers.” These tools must send requests and identify the target web pages (if they haven't already).
Web scrapers also include data parsing to extract the target data set and filter out irrelevant data. Data parsers transform unprocessed data into a readable format, making it ready to use anytime.
|
👍 Helpful Article Choosing a suitable data parsing tool is crucial in web scraping to guarantee the accuracy of the collected and transformed data. Check out some of the best data parsing tools that you can use. |
Web scraping and web crawling are not illegal. However, the legality of these activities depends on the type of data it scrapes or crawls.
In web scraping, it's legal to scrape publicly available information. The activity must follow the target website's robot.txt file to avoid legal issues. The same principle also applies to web crawling.
Web scraping and crawling can go hand-in-hand, but each process has specific use cases.
Here are the everyday use cases of web scraping:

Web scraping collects data for market analysis and competitive research. In this case, the usual scraped data sets are prices, descriptions, reviews, offers, etc.
|
👍 Helpful Article The process of scraping eCommerce websites depends on what the target data is. Use this guide on scraping eCommerce websites to know how. |
This use case is for business purposes or purely academic. No matter the industry, the Internet is an excellent resource of valuable data.
There are a lot of valuable tools for lead generation. Most of them use web scraping methods to extract data from potential clients.
Meanwhile, web crawling is commonly used for the following:
Search engines are the most prominent web crawlers on the Internet. They crawl sites and pages, read their content, and index them for web searches.
This process is manually doable. However, it can be more efficient and faster by using web crawling tools and techniques.
This application is where web crawling and web scraping overlap. A web scraper tool uses “crawling” methods to identify the specific URLs with the needed data set.
Both processes share some benefits, while some advantages are exclusive for each one.
To start up, here are the benefits of web crawling/scraping.
People who say web crawling/scraping usually refer to automated methods. These methods include web scraping APIs, crawling bots, and more.
They save much time and resources compared to manual research techniques.
|
✅ Pro Tip Though APIs save time and resources than manual processes, there are better ways to do it. For instance, you can use Bright Data's Scraping Browser. This tool works better than APIs and saves you money from the API fees. |
Web crawling/scraping tools are becoming more accurate. As a result, they reduce the risk of human error—leading to a higher quality of data.
Powerful web crawling/scraping tools can achieve a depth and comprehensiveness that humans can't do. This is crucial in keeping up with today's demand for information.
Outdated information is still valuable for historical analysis. However, an updated data set is crucial for any business to adapt to significant changes.
Scraping and crawling tools can gather real-time data. Moreover, they can capture data differences every minute.
Web crawlers and scrapers are legal, but websites do not welcome them with open arms for a good reason. Here are some of the challenges of these activities:
Anti-crawler/scraper tools detect and block scraping or crawling activities. Scrapers/crawlers are often unwelcome due to the strain they cause on web servers.
Some sites are challenging to scrape or crawl, even though their data are “public.”
IP blocking and CAPTCHA tests are unavoidable when conducting scraping/crawling activities.
You can solve this issue by using proxies. However, these proxies are a temporary fix as they will also be blocked eventually.
|
✅ Pro Tip Overcome IP blocking and CAPTCHA using rotating proxies instead of static ones. Rotating proxies change per request or within specific intervals, reducing the chances of getting blocked by a website's security. |
Rather than a challenge, it is more of a matter of legal responsibility. If the site owners do not allow crawling or scraping, it is better to comply and find an alternative.
Web crawling and web scraping activities overlap, but they are entirely separate concepts.
Learning the differences between the two approaches will help you decide which method suits your project, what data you need, and what to do with the data after collecting.
Web scraping is data extraction over the internet. Data scraping does the same thing, but not necessarily online–such as scraping offline records or books.
Yes. Google uses web crawling techniques to index websites and web pages.
Python is widely considered the best programming for web scraping. However, some may argue that C++ is faster and better or that Javascript through Node.js has more useful libraries for web scraping.
No, and you can find this information on any website’s robot.txt file appended to their domain names.
SHARE:
Your email address will not be published.
Updated · Feb 11, 2024
Updated · Feb 11, 2024
Updated · Feb 08, 2024
Updated · Feb 05, 2024



