
Wiki Guide: How to Extract Data from Wikipedia Using an API?
![Muninder Adavelli]()

Muninder Adavelli
Updated · Feb 11, 2024
Updated · Nov 16, 2023
Meet Success Eriamiantoe, a dynamic and optimistic individual who thrives on fresh ideas and energy.... | See full bio
Lorie is an English Language and Literature graduate passionate about writing, research, and learnin... | See full bio
This page may contain links to our partners’ products and services, which allows us to keep our website sustainable. Тechjury.net may receive a compensation when you sign up and / or purchase a product or a service using our links. As an Amazon Associate we earn commissions from qualified purchases. This comes at no extra cost to you. On the contrary, these partnerships often allow us to give you discounts and lower prices. However, all opinions expressed on our site are solely ours, and this content is in no way provided or influenced by any of our partners.
Whether it's market research, competitive analysis, or staying updated on trends, unlocking information available on the web through data scraping has become indispensable for individuals and businesses. However, data extraction has become increasingly challenging as websites refine their anti-scraping defenses.
Proxies play a vital role in getting around such anti-scraping measures. They act as intermediaries between the scraper and the target website, masking the scraper's identity.
Two primary categories of proxies commonly used for web scraping are data center proxies and residential proxies. Each type has its merits and drawbacks, making it essential to weigh them carefully to determine the most suitable one for your scraping use case.
In this article, we will explore and compare residential proxies and data center proxies, shedding light on their specific use cases and essential factors to consider when choosing a proxy provider. We'll also look at Bright Data's Scraping Browser, an all-in-one scraping and proxy management solution with a cutting-edge proxy infrastructure.
|
Key Takeaways |
|
|---|---|
 |
Proxies are crucial for successful web scraping, enhancing security, privacy, and performance. |
|
Datacenter proxies are cost-effective and scalable but easily detectable and prone to IP bans. |
|
Residential proxies offer higher anonymity, ideal for sensitive scraping tasks and bypassing geo-restrictions, but are more expensive and may have slower speeds. |
|
When choosing a proxy provider, consider project needs, network size, pricing, performance, features, and ethical compliance. |
|
Bright Data's Scraping Browser provides a comprehensive solution with diverse, high-quality IPs, automated IP rotation, scalability, legal compliance, and reliability for seamless data extraction. |
When it comes to web scraping, proxy servers are crucial to improve security, privacy, and performance.
As previously mentioned, a proxy is an intermediary between a web scraper and the target website. Instead of directly connecting to the website, the scraper routes its requests through the proxy server, masking its true identity.

Whenever a user requests to access a web page, a proxy server receives the request first. It authenticates and filters the request before sending them to a server. The destination server responds to the proxy, which relays the response to the user.
 |
Helpful Articles: If you want to learn more about proxies, check out Techjury’s article on private proxies and fresh proxies. |
This lends several crucial benefits to the web scraping process:
Now that we've discussed the significance of proxies, let's look at two types of proxies that are particularly essential to the web scraping process: data center and residential.
|
In a nutshell. . . Proxies are essential for web scraping, providing anonymity, improved performance, and data security. They help evade anti-scraping mechanisms, enable parallel scraping, and bypass geo-restrictions. Two vital types are data centers and residential proxies. |
Datacenter (DC) proxies are widely used among the different types proxy servers for web scraping. These proxies use IP addresses from data centers, facilities designed to host computer systems, and networking infrastructure.

Unlike residential proxies that use IP addresses provided by Internet Service Providers (ISPs) or residential users, data center proxies are not associated with physical locations or real Internet users. Instead, they are created and distributed by third-party data center providers, offering a range of benefits that suit specific web scraping needs.
Here are some key advantages of data center proxies:
However, data center proxies also come with some limitations. These can include:
|
Warning: Persistent and aggressive scraping from a single IP address can lead to IP blocks and rate limiting, hindering the process further. |
|
In a nutshell. . . Datacenter proxies are popular for web scraping due to their affordability, speed, and ability to bypass geo-restrictions. They are not associated with real users, which can lead to detection and potential IP bans. Residential proxies will be explored as an alternative with their own advantages and drawbacks. |
Let us now explore using residential proxies, an alternative approach with advantages and drawbacks.
Residential proxies are specialized proxy servers that route web requests through real residential IP addresses. Instead of using proxies sourced from data centers, they use IP addresses provided by Internet Service Providers (ISPs) to simulate the identity of real residential users.

These proxies are designed to appear as if real people are accessing the web, making them a popular choice for web scraping tasks that require a higher level of anonymity, stealth, and evasion of anti-scraping measures.
Here are some advantages of using residential proxies in your web scraping process:
However, residential proxies, too, can have their drawbacks. These include:
Summing up the points previously mentioned, here is a table highlights the differences between residential and data centre proxies:
|
Feature |
Residential proxies |
Datacenter Proxies |
|
Anonymity |
more anonymity |
less anonymity |
|
Scalability |
less scalable |
more scalable |
|
Cost |
more expensive |
less expensive |
|
Source of IP Addresses |
real residential users and ISPS |
data centers |
In the next section, we’ll consider some factors when choosing a proxy provider for your web scraping project.
 |
Note: It’s worth bearing in mind that regardless of whether you opt for datacenter proxies or residential proxies, the choice of the proxy provider can significantly impact the success of your scraping project. |
Now that we have explored the pros and cons of both residential and datacenter proxies, it's essential to understand how to make an informed decision when selecting the best proxy provider so that you can navigate the complexities of data extraction efficiently. Here are some of the factors you should consider:
Proxy services offer different types of proxies, each with its unique purposes and benefits. Assess your web scraping project's requirements to determine whether datacenter proxies, residential proxies, or both are the ideal fit.
For example, any website not scanning for human-like behavior or employing complex bot-detection measures would be a good use case for datacenter proxies. However, residential proxies would be better for scraping more sensitive websites.
The size of the proxy network and the range of IP addresses it controls play a crucial role in the effectiveness of your web scraping activities. A larger network provides more options and reduces the risk of overcrowding, ensuring improved performance and anonymity. A well-distributed IP pool facilitates effective rotation and distribution of addresses, aiding in bypassing restrictions and minimizing the chance of detection.
You must also assess the provider's infrastructure to ensure stability, uptime, and fast connection speeds. Multiple strategically placed server locations further enhance coverage and access to proxies from various regions.
Understand the pricing structure the proxy provider offers and how it aligns with your budget and needs. Different pricing models exist, such as:
 |
Pro Tip Look for proxy providers offering free trials and refund policies, allowing you to test their service and secure your investment. However, you have to ensure that it’s safe to use a free proxy. |
Prioritize high availability and uptime when choosing a reliable proxy service. You must also evaluate the proxy provider's performance, including:
Customer reviews and feedback provide valuable insights into the provider's reliability and scalability in handling varying traffic volumes.
Select a provider that offers tools suitable for your specific project requirements. Consider the features and tools the proxy provider offers to enhance your web-scaping capabilities, including:
Reliable customer service is vital for prompt issue resolution and uninterrupted access to proxies. A skilled support team can guide you through setup, configuration, and troubleshooting, ensuring a seamless web scraping experience.
 |
Pro Tip Look for providers offering 24/7 support and multiple communication channels, including live chat, e-mail, or dedicated account managers. |
7. Prioritize Ethical Compliance
Ensure the proxy provider operates transparently, prioritizing security, privacy, and ethical practices. Verify the implementation of robust security measures, data encryption, and adherence to privacy regulations. Choose a provider committed to the responsible use of proxies, avoiding illicit activities, and safeguarding user data.
With so many factors to consider, choosing the right proxy provider for web scraping can be daunting. But what if there was a comprehensive solution that simplified the entire process while considering all of the above-mentioned factors?
This is precisely where Bright Data’s Scraping Browser comes in.
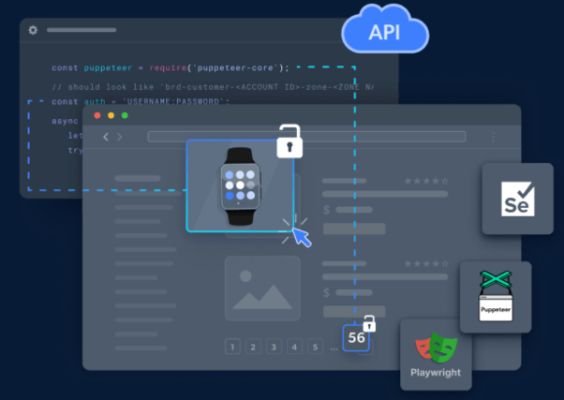
The Scraping Browser is a fully graphical user interface (GUI) Chrome instance that operates on Bright Data's servers. A WebSocket connection can be remotely connected to headless browsers like Puppeteer and Playwright. Its sophisticated unlocker technology enables it to bypass complex anti-scraping bot-detection measures effectively.
Notably, the Scraping Browser comes in-built with Bright Data's cutting-edge proxy infrastructure, which offers an extensive network of diverse, high-quality IP addresses sourced and vetted ethically —General Data Protection Regulation (GPDR) and the California Consumer Privacy Act compliant.
By using Bright Data’s advanced proxy infrastructure, you can effortlessly achieve seamless data extraction for invaluable location-based insights.
Here are some of the benefits of using Bright Data’s proxy infrastructure:
 |
Note: The Scraping Browser uses the waterfall solution, where requests begin with data center IPs, progress to residential IPs for sensitive pages, and finally, resort to mobile IPs if earlier attempts are unsuccessful. |
Manually integrating proxies into your scraping script can be a tedious, messy, and time-consuming process. Fortunately, Scraping Browser comes in-built with Bright Data’s proxy infrastructure, eliminating the need for external infrastructure or advanced coding with third-party libraries.
You can use either data center proxies or ethically acquired residential proxies as per your use case. It also adeptly handles IP rotation, throttling, and retries automatically, making for a comprehensive and highly scalable solution for your data collection needs.
The Scraping Browser comes with a free trial and can be easily integrated into existing libraries like Playwright or Puppeteer. You can look up instructions to get started here.
 |
Helpful Articles: Techjury has other data scraping-related articles. Check out our guides on how to scrape Google Search data and 5 simple methods to scrape e-commerce websites. |
No, data center proxies are more efficient than residential proxies if you need to scrape at higher volumes. However, datacenter proxies are more susceptible to website anti-scrapping methods.
Yes, you can use reverse proxies to restrict and monitor users’ access to webservers with sensitive data. A reverse proxy protects web servers against potential attacks while imrpoving performance and reliability.
The legality of using residential proxies depends on how it is used. If used for legitimate purposes such as market research, ad verification, and web scraping, this proxy is completely legal. However, it becomes illegal if used for fraud, spamming, or phishing.
SHARE:
Your email address will not be published.
Updated · Feb 11, 2024
Updated · Feb 11, 2024
Updated · Feb 08, 2024
Updated · Feb 05, 2024



